Chapter 6 File system¶
The purpose of a file system is to organize and store data. File systems typicallysupport sharing of data among users and applications, as well as persistence so thatdata is still available after a reboot.
The xv6 file system provides Unix-like files, directories, and pathnames (see Chapter 0), and stores its data on an IDE disk for persistence (see Chapter 3). The file system addresses several challenges:
- The file system needs on-disk data structures to represent the tree of named directories and files, to record the identities of the blocks that hold each file’s content, and to record which areas of the disk are free.
- The file system must support crash recovery. That is, if a crash (e.g., powerfailure) occurs, the file system must still work correctly after a restart. The risk isthat a crash might interrupt a sequence of updates and leave inconsistent on-diskdata structures (e.g., a block that is both used in a file and marked free).
- Different processes may operate on the file system at the same time, and must co-ordinate to maintain invariants.
- Accessing a disk is orders of magnitude slower than accessing memory, so the filesystem must maintain an in-memory cache of popular blocks.
The rest of this chapter explains how xv6 addresses these challenges.
Overview¶
The xv6 file system implementation is organized in 6 layers, as shown in Figure6-1. The lowest layer reads and writes blocks on the IDE disk through the buffercache, which synchronizes access to disk blocks, making sure that only one kernel process at a time can edit the file system data stored in any particular block. The secondlayer allows higher layers to wrap updates to several blocks in a transaction, to ensure that the blocks are updated atomically (i.e., all of them are updated or none).The third layer provides unnamed files, each represented using an inode and a sequence of blocks holding the file’s data. The fourth layer implements directories as aspecial kind of inode whose content is a sequence of directory entries, each of whichcontains a name and a reference to the named file’s inode. The fifth layer provides hierarchical path names like /usr/rtm/xv6/fs.c, using recursive lookup. The final layer abstracts many Unix resources (e.g., pipes, devices, files, etc.) using the file systeminterface, simplifying the lives of application programmers.
The file system must have a plan for where it stores inodes and content blocks onthe disk. To do so, xv6 divides the disk into several sections, as shown in Figure 6-2.The file system does not use block 0 (it holds the boot sector). Block 1 is called thesuperblock; it contains metadata about the file system (the file system size in blocks, the number of data blocks, the number of inodes, and the number of blocks in thelog). Blocks starting at 2 hold inodes, with multiple inodes per block. After thosecome bitmap blocks tracking which data blocks in use. Most of the remaining blocksare data blocks, which hold file and directory contents. The blocks at the end of thedisk hold a log that is part of the transaction layer.The rest of this chapter discusses each layer, starting from the bottom. Look outfor situations where well-chosen abstractions at lower layers ease the design of higherones.
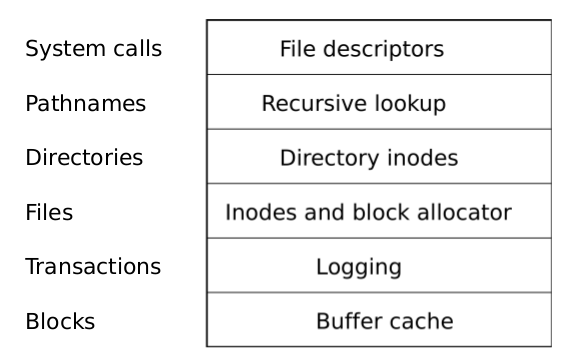
Figure 6-1. Layers of the xv6 file system.
Buffer cache Layer¶
The buffer cache has two jobs: (1) synchronize access to disk blocks to ensurethat only one copy of a block is in memory and that only one kernel thread at a timeuses that copy; (2) cache popular blocks so that they don’t to be reread from the slowdisk. The code is in bio.c.
The main interface exported by the buffer cache consists of bread and bwrite;the former obtains a buffer containing a copy of a block which can be read or modified in memory, and the latter writes a modified buffer to the appropriate block on thedisk. A kernel thread must release a buffer by calling brelse when it is done with it.
The buffer cache synchronizes access to each block by allowing at most one kernel thread to have a reference to the block’s buffer. If one kernel thread has obtained areference to a buffer but hasn’t yet released it, other threads’ calls to bread for thesame block will wait. Higher file system layers rely on the buffer cache’s block sychronization to help them maintain invariants.
The buffer cache has a fixed number of buffers to hold disk blocks, which meansthat if the file system asks for a block that is not already in the cache, the buffer cachemust recycle a buffer currently holding some other block. The buffer cache recycles theleast recently used buffer for the new block. The assumption is that the least recentlyused buffer is the one least likely to be used again soon.

Figure 6-2. Structure of the xv6 file system. The header fs.h (3650) contains constants and data structures describing the exact layout of the file system.
Code: Buffer cache¶
The buffer cache is a doubly-linked list of buffers. The function binit, called bymain (1231), initializes the list with the NBUF buffers in the static array buf (4050-4059).All other access to the buffer cache refers to the linked list via bcache.head, not thebuf array.
A buffer has three state bits associated with it. B_VALID indicates that the buffercontains a valid copy of the block. B_DIRTY indicates that the buffer content has beenmodified and needs to be written to the disk. B_BUSY indicates that some kernelthread has a reference to this buffer and has not yet released it.
Bread (4102) calls bget to get a buffer for the given sector (4106). If the bufferneeds to be read from disk, bread calls iderw to do that before returning the buffer.
Bget (4066) scans the buffer list for a buffer with the given device and sector numbers (4073-4084). If there is such a buffer, and the buffer is not busy, bget sets theB_BUSY flag and returns (4076-4083). If the buffer is already in use, bget sleeps on thebuffer to wait for its release. When sleep returns, bget cannot assume that the bufferis now available. In fact, since sleep released and reacquired buf_table_lock, thereis no guarantee that b is still the right buffer: maybe it has been reused for a differentdisk sector. Bget has no choice but to start over (4082), hoping that the outcome willbe different this time.
If bget didn’t have the goto statement, then the race in Figure 6-3 could occur.The first process has a buffer and has loaded sector 3 in it. Now two other processescome along. The first one does a get for buffer 3 and sleeps in the loop for cachedblocks. The second one does a get for buffer 4, and could sleep on the same bufferbut in the loop for freshly allocated blocks because there are no free buffers and thebuffer that holds 3 is the one at the front of the list and is selected for reuse. Thefirst process releases the buffer and wakeup happens to schedule process 3 first, and itwill grab the buffer and load sector 4 in it. When it is done it will release the buffer(containing sector 4) and wakeup process 2. Without the goto statement process 2will mark the buffer BUSY, and return from bget, but the buffer contains sector 4, instead of 3. This error could result in all kinds of havoc, because sectors 3 and 4 havedifferent content; xv6 uses them for storing inodes.
If there is no buffer for the given sector, bget must make one, possibly reusing abuffer that held a different sector. It scans the buffer list a second time, looking for ablock that is not busy: any such block can be used. Bget edits the block metadata torecord the new device and sector number and mark the block busy before returningthe block (4091-4093). Note that the assignment to flags not only sets the B_BUSY bitbut also clears the B_VALID and B_DIRTY bits, making sure that bread will refresh the buffer data from disk rather than use the previous block’s contents.
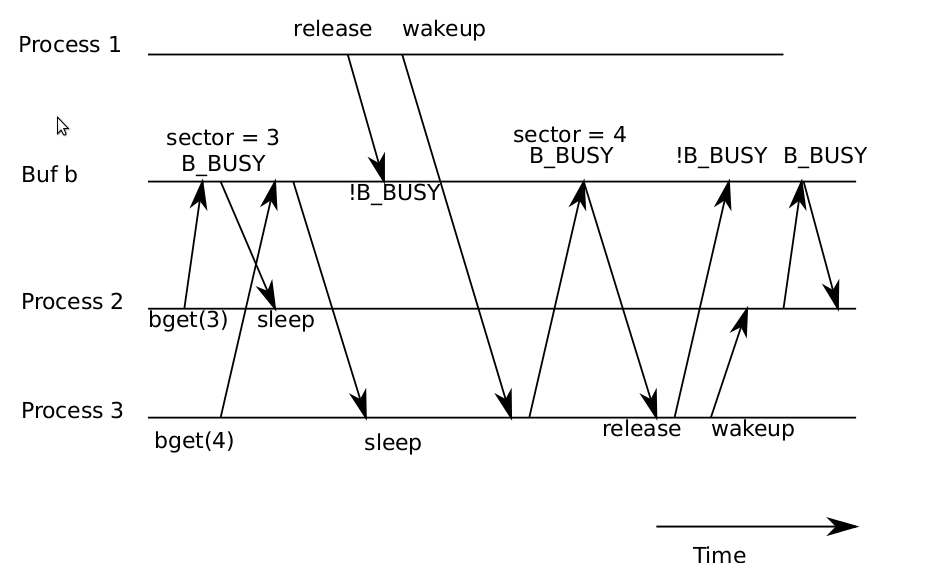
Figure 6-3. A race resulting in process 3 receiving a buffer containing block 4, even though it asked forblock 3.
Because the buffer cache is used for synchronization, it is important that there isonly ever one buffer for a particular disk sector. The assignments (4089-4091) are onlysafe because bget’s first loop determined that no buffer already existed for that sector,and bget has not given up buf_table_lock since then.
If all the buffers are busy, something has gone wrong: bget panics. A moregraceful response might be to sleep until a buffer became free, though there wouldthen be a possibility of deadlock.
Once bread has returned a buffer to its caller, the caller has exclusive use of thebuffer and can read or write the data bytes. If the caller does write to the data, it mustcall bwrite to write the changed data to disk before releasing the buffer. Bwrite (4114)sets the B_DIRTY flag and calls iderw to write the buffer to disk.
When the caller is done with a buffer, it must call brelse to release it. (The namebrelse, a shortening of b-release, is cryptic but worth learning: it originated in Unixand is used in BSD, Linux, and Solaris too.) Brelse (4125) moves the buffer from itsposition in the linked list to the front of the list (4132-4137), clears the B_BUSY bit, andwakes any processes sleeping on the buffer. Moving the buffer has the effect that thebuffers are ordered by how recently they were used (meaning released): the first bufferin the list is the most recently used, and the last is the least recently used. The twoloops in bget take advantage of this: the scan for an existing buffer must process theentire list in the worst case, but checking the most recently used buffers first (startingat bcache.head and following next pointers) will reduce scan time when there isgood locality of reference. The scan to pick a buffer to reuse picks the least recentlyused block by scanning backward (following prev pointers).
Logging layer¶
One of the most interesting problems in file system design is crash recovery. Theproblem arises because many file system operations involve multiple writes to the disk,and a crash after a subset of the writes may leave the on-disk file system in an incon-sistent state. For example, depending on the order of the disk writes, a crash during filedeletion may either leave a directory entry pointing to a free inode, or it may leave anallocated but unreferenced inode. The latter is relatively benign, but a directory entrythat refers to a freed inode is likely to cause serious problems after a reboot.
Xv6 solves the problem of crashes during file system operations with a simple version of logging. An xv6 system call does not directly write the on-disk file system datastructures. Instead, it places a description of all the disk writes it wishes to make in alog on the disk. Once the system call has logged all of its writes, it writes a specialcommit record to the disk indicating that the log contains a complete operation. Atthat point the system call copies the writes to the on-disk file system data structures.After those writes have completed, the system call erases the log on disk.
If the system should crash and reboot, the file system code recovers from thecrash as follows, before running any processes. If the log is marked as containing acomplete operation, then the recovery code copies the writes to where they belong inthe on-disk file system. If the log is not marked as containing a complete operation,the recovery code ignores the log. The recovery code finishes by erasing the log.
Why does xv6’s log solve the problem of crashes during file system operations? If the crash occurs before the operation commits, then the log on disk will not bemarked as complete, the recovery code will ignore it, and the state of the disk will beas if the operation had not even started. If the crash occurs after the operation commits, then recovery will replay all of the operation’s writes, perhaps repeating them ifthe operation had started to write them to the on-disk data structure. In either case,the log makes operations atomic with respect to crashes: after recovery, either all of theoperation’s writes appear on the disk, or none of them appear.
Log design¶
The log resides at a known fixed location at the end of the disk. It consists of aheader block followed by a sequence of data blocks. The header block contains an array of sector numbers, one for each of the logged data blocks. The header block alsocontains the count of logged blocks. Xv6 writes the header block when a transactioncommits, but not before, and sets the count to zero after copying the logged blocks tothe file system. Thus a crash midway through a transaction will result in a count ofzero in the log’s header block; a crash after a commit will result in a non-zero count.
Each system call’s code indicates the start and end of the sequence of writes thatmust be atomic; we’ll call such a sequence a transaction, though it is much simplerthan a database transaction. Only one system call can be in a transaction at any onetime: other processes must wait until any ongoing transaction has finished. Thus thelog holds at most one transaction at a time.
Xv6 does not allow concurrent transactions, in order to avoid the following kindof problem. Suppose transaction X has written a modification to an inode into thelog. Concurrent transaction Y then reads a different inode in the same block, updatesthat inode, writes the inode block to the log, and commits. This is a disaster: the inodeblock that Y’s commit writes to the disk contains modifications by X, which has notcommitted. A crash and recovery at this point would expose one of X’s modificationsbut not all, thus breaking the promise that transactions are atomic. There are sophisticated ways to solve this problem; xv6 solves it by outlawing concurrent transactions.
Xv6 allows read-only system calls to execute concurrently with a transaction. Inode locks cause the transaction to appear atomic to the read-only system call.
Xv6 dedicates a fixed amount of space on the disk to hold the log. No systemcall can be allowed to write more distinct blocks than there is space in the log. This isnot a problem for most system calls, but two of them can potentially write manyblocks: write and unlink. A large file write may write many data blocks and manybitmap blocks as well as an inode block; unlinking a large file might write manybitmap blocks and an inode. Xv6’s write system call breaks up large writes into multiple smaller writes that fit in the log, and unlink doesn’t cause problems because inpractice the xv6 file system uses only one bitmap block.
Code: logging¶
A typical use of the log in a system call looks like this:
begin_trans();
...
bp = bread(...);
bp->data[...] = ...;
log_write(bp);
...
commit_trans();
begin_trans (4277) waits until it obtains exclusive use of the log and then returns.log_write (4325) acts as a proxy for bwrite; it appends the block’s new content tothe log on disk and records the block’s sector number in memory. log_write leavesthe modified block in the in-memory buffer cache, so that subsequent reads of theblock during the transaction will yield the modified block. log_write notices when ablock is written multiple times during a single transaction, and overwrites the block’sprevious copy in the log.
commit_trans (4301) first writes the log’s header block to disk, so that a crash afterthis point will cause recovery to re-write the blocks in the log. commit_trans thencalls install_trans (4221) to read each block from the log and write it to the properplace in the file system. Finally commit_trans writes the log header with a count ofzero, so that a crash after the next transaction starts will result in the recovery code ignoring the log.
recover_from_log (4268) is called from initlog (4205), which is called duringboot before the first user process runs. (2544) It reads the log header, and mimics theactions of commit_trans if the header indicates that the log contains a committed transaction.
An example use of the log occurs in filewrite (5352). The transaction looks likethis:
begin_trans();
ilock(f->ip);
r = writei(f->ip, ...);
iunlock(f->ip);
commit_trans();
This code is wrapped in a loop that breaks up large writes into individual transactionsof just a few sectors at a time, to avoid overflowing the log. The call to writei writesmany blocks as part of this transaction: the file’s inode, one or more bitmap blocks,and some data blocks. The call to ilock occurs after the begin_trans as part of anoverall strategy to avoid deadlock: since there is effectively a lock around each transaction, the deadlock-avoiding lock ordering rule is transaction before inode.
Code: Block allocator¶
File and directory content is stored in disk blocks, which must be allocated from afree pool. xv6’s block allocator maintains a free bitmap on disk, with one bit perblock. A zero bit indicates that the corresponding block is free; a one bit indicates thatit is in use. The bits corresponding to the boot sector, superblock, inode blocks, andbitmap blocks are always set.
The block allocator provides two functions: balloc allocates a new disk block,and bfree frees a block. Balloc (4454) starts by calling readsb to read the superblockfrom the disk (or buffer cache) into sb. balloc decides which blocks hold the datablock free bitmap by calculating how many blocks are consumed by the boot sector,the superblock, and the inodes (using BBLOCK). The loop (4462) considers every block,starting at block 0 up to sb.size, the number of blocks in the file system. It looks fora block whose bitmap bit is zero, indicating that it is free. If balloc finds such ablock, it updates the bitmap and returns the block. For efficiency, the loop is split intotwo pieces. The outer loop reads each block of bitmap bits. The inner loop checks allBPB bits in a single bitmap block. The race that might occur if two processes try toallocate a block at the same time is prevented by the fact that the buffer cache onlylets one process use a block at a time.
Bfree (4481) finds the right bitmap block and clears the right bit. Again the exclusive use implied by bread and brelse avoids the need for explicit locking.
Inodes¶
The term inode can have one of two related meanings. It might refer to the on-disk data structure containing a file’s size and list of data block numbers. Or ‘‘inode’’might refer to an in-memory inode, which contains a copy of the on-disk inode aswell as extra information needed within the kernel.
All of the on-disk inodes are packed into a contiguous area of disk called the inode blocks. Every inode is the same size, so it is easy, given a number n, to find the nth inode on the disk. In fact, this number n, called the inode number or inumber, ishow inodes are identified in the implementation.
The on-disk inode is defined by a struct dinode (3676). The type field distinguishes between files, directories, and special files (devices). A type of zero indicatesthat an on-disk inode is free. The nlink field counts the number of directory entriesthat refer to this inode, in order to recognize when the inode should be freed. Thesize field records the number of bytes of content in the file. The addrs array recordsthe block numbers of the disk blocks holding the file’s content.
The kernel keeps the set of active inodes in memory; struct inode (3762) is thein-memory copy of a struct dinode on disk. The kernel stores an inode in memoryonly if there are C pointers referring to that inode. The ref field counts the number ofC pointers referring to the in-memory inode, and the kernel discards the inode frommemory if the reference count drops to zero. The iget and iput functions acquireand release pointers to an inode, modifying the reference count. Pointers to an inodecan come from file descriptors, current working directories, and transient kernel codesuch as exec.
Holding a pointer to an inode returned by iget() guarantees that the inode willstay in the cache and will not be deleted (and in particular will not be re-used for adifferent file). Thus a pointer returned by iget() is a weak form of lock, though itdoes not entitle the holder to actually look at the inode. Many parts of the file systemcode depend on this behavior of iget(), both to hold long-term references to inodes(as open files and current directories) and to prevent races while avoiding deadlock incode that manipulates multiple inodes (such as pathname lookup).
The struct inode that iget returns may not have any useful content. In orderto ensure it holds a copy of the on-disk inode, code must call ilock. This locks theinode (so that no other process can ilock it) and reads the inode from the disk, if ithas not already been read. iunlock releases the lock on the inode. Separating acquisition of inode pointers from locking helps avoid deadlock in some situations, for example during directory lookup. Multiple processes can hold a C pointer to an inodereturned by iget, but only one process can lock the inode at a time.
The inode cache only caches inodes to which kernel code or data structures holdC pointers. Its main job is really synchronizing access by multiple processes, notcaching. If an inode is used frequently, the buffer cache will probably keep it in memory if it isn’t kept by the inode cache.
Code: Inodes¶
To allocate a new inode (for example, when creating a file), xv6 calls ialloc(4603). Ialloc is similar to balloc: it loops over the inode structures on the disk, oneblock at a time, looking for one that is marked free. When it finds one, it claims it bywriting the new type to the disk and then returns an entry from the inode cache withthe tail call to iget (4620). The correct operation of ialloc depends on the fact thatonly one process at a time can be holding a reference to bp: ialloc can be sure thatsome other process does not simultaneously see that the inode is available and try to claim it.
Iget (4654) looks through the inode cache for an active entry (ip->ref > 0) withthe desired device and inode number. If it finds one, it returns a new reference to thatinode. (4663-4667). As iget scans, it records the position of the first empty slot (4668-4669), which it uses if it needs to allocate a cache entry.
Callers must lock the inode using ilock before reading or writing its metadata orcontent. Ilock (4703) uses a now-familiar sleep loop to wait for ip->flag’s I_BUSY bitto be clear and then sets it (4712-4714). Once ilock has exclusive access to the inode, itcan load the inode metadata from the disk (more likely, the buffer cache) if needed.The function iunlock (4735) clears the I_BUSY bit and wakes any processes sleeping inilock.
Iput (4756) releases a C pointer to an inode by decrementing the reference count(4772). If this is the last reference, the inode’s slot in the inode cache is now free andcan be re-used for a different inode.
If iput sees that there are no C pointer references to an inode and that the inodehas no links to it (occurs in no directory), then the inode and its data blocks must befreed. Iput relocks the inode; calls itrunc to truncate the file to zero bytes, freeingthe data blocks; sets the inode type to 0 (unallocated); writes the change to disk; andfinally unlocks the inode (4759-4771).
The locking protocol in iput deserves a closer look. The first part worth examining is that when locking ip, iput simply assumed that it would be unlocked, insteadof using a sleep loop. This must be the case, because the caller is required to unlockip before calling iput, and the caller has the only reference to it (ip->ref == 1). Thesecond part worth examining is that iput temporarily releases (4764) and reacquires(4768) the cache lock. This is necessary because itrunc and iupdate will sleep duringdisk i/o, but we must consider what might happen while the lock is not held. Specifically, once iupdate finishes, the on-disk structure is marked as available for use, and aconcurrent call to ialloc might find it and reallocate it before iput can finish. Ialloc will return a reference to the block by calling iget, which will find ip in thecache, see that its I_BUSY flag is set, and sleep. Now the in-core inode is out of synccompared to the disk: ialloc reinitialized the disk version but relies on the caller toload it into memory during ilock. In order to make sure that this happens, iputmust clear not only I_BUSY but also I_VALID before releasing the inode lock. It doesthis by zeroing flags (4769).
Code: Inode content¶
The on-disk inode structure, struct dinode, contains a size and an array ofblock numbers (see Figure 6-4). The inode data is found in the blocks listed in thedinode’s addrs array. The first NDIRECT blocks of data are listed in the first NDIRECTentries in the array; these blocks are called direct blocks. The next NINDIRECTblocks of data are listed not in the inode but in a data block called the indirectblock. The last entry in the addrs array gives the address of the indirect block. Thusthe first 6 kB (NDIRECT×BSIZE) bytes of a file can be loaded from blocks listed in theinode, while the next 64kB (NINDIRECT×BSIZE) bytes can only be loaded after consulting the indirect block. This is a good on-disk representation but a complex one for clients. The function bmap manages the representation so that higher-level routinessuch as readi and writei, which we will see shortly. Bmap returns the disk blocknumber of the bn’th data block for the inode ip. If ip does not have such a block yet,bmap allocates one.
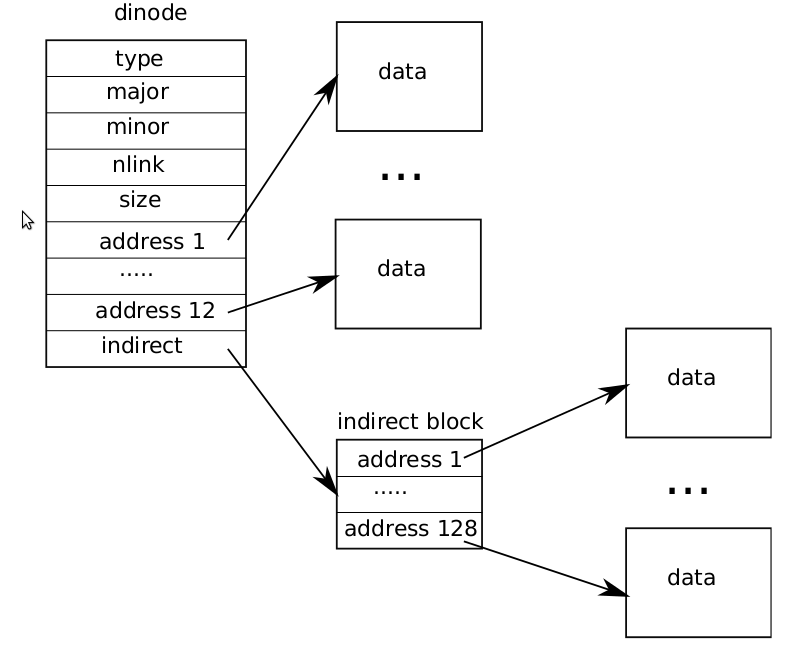
Figure 6-4. The representation of a file on disk.
The function bmap (4810) begins by picking off the easy case: the first NDIRECTblocks are listed in the inode itself (4815-4819). The next NINDIRECT blocks are listed inthe indirect block at ip->addrs[NDIRECT]. Bmap reads the indirect block (4826) andthen reads a block number from the right position within the block (4827). If the blocknumber exceeds NDIRECT+NINDIRECT, bmap panics: callers are responsible for not asking about out-of-range block numbers.
Bmap allocates block as needed. Unallocated blocks are denoted by a block number of zero. As bmap encounters zeros, it replaces them with the numbers of freshblocks, allocated on demand. (4816-4817, 4824-4825).
Bmap allocates blocks on demand as the inode grows; itrunc frees them, resettingthe inode’s size to zero. Itrunc (4856) starts by freeing the direct blocks (4862-4867) andthen the ones listed in the indirect block (4872-4875), and finally the indirect block itself(4877-4878).
Bmap makes it easy to write functions to access the inode’s data stream, like readiand writei. Readi (4902) reads data from the inode. It starts making sure that the offset and count are not reading beyond the end of the file. Reads that start beyond theend of the file return an error (4913-4914) while reads that start at or cross the end ofthe file return fewer bytes than requested (4915-4916). The main loop processes each block of the file, copying data from the buffer into dst (4918-4923). The functionwritei (4952) is identical to readi, with three exceptions: writes that start at or crossthe end of the file grow the file, up to the maximum file size (4965-4966); the loop copiesdata into the buffers instead of out (4971); and if the write has extended the file, writeimust update its size (4976-4979).
Both readi and writei begin by checking for ip->type == T_DEV. This casehandles special devices whose data does not live in the file system; we will return tothis case in the file descriptor layer.
The function stati (4423) copies inode metadata into the stat structure, which isexposed to user programs via the stat system call.
Code: directory layer¶
A directory is implemented internally much like a file. Its inode has type T_DIRand its data is a sequence of directory entries. Each entry is a struct dirent (3700),which contains a name and an inode number. The name is at most DIRSIZ (14) char-acters; if shorter, it is terminated by a NUL (0) byte. Directory entries with inodenumber zero are free.
The function dirlookup (5011) searches a directory for an entry with the givenname. If it finds one, it returns a pointer to the corresponding inode, unlocked, andsets *poff to the byte offset of the entry within the directory, in case the caller wishesto edit it. If dirlookup finds an entry with the right name, it updates *poff, releasesthe block, and returns an unlocked inode obtained via iget. Dirlookup is the reasonthat iget returns unlocked inodes. The caller has locked dp, so if the lookup was for., an alias for the current directory, attempting to lock the inode before returningwould try to re-lock dp and deadlock. (There are more complicated deadlock scenarios involving multiple processes and .., an alias for the parent directory; . is not theonly problem.) The caller can unlock dp and then lock ip, ensuring that it only holdsone lock at a time.
The function dirlink (5052) writes a new directory entry with the given nameand inode number into the directory dp. If the name already exists, dirlink returnsan error (5058-5062). The main loop reads directory entries looking for an unallocatedentry. When it finds one, it stops the loop early (5022-5023), with off set to the offset ofthe available entry. Otherwise, the loop ends with off set to dp->size. Either way,dirlink then adds a new entry to the directory by writing at offset off (5072-5075).
Code: Path names¶
Path name lookup involves a succession of calls to dirlookup, one for each pathcomponent. Namei (5189) evaluates path and returns the corresponding inode. Thefunction nameiparent is a variant: it stops before the last element, returning the inodeof the parent directory and copying the final element into name. Both call the generalized function namex to do the real work.
Namex (5154) starts by deciding where the path evaluation begins. If the path begins with a slash, evaluation begins at the root; otherwise, the current directory (5158-5161). Then it uses skipelem to consider each element of the path in turn (5163). Eachiteration of the loop must look up name in the current inode ip. The iteration beginsby locking ip and checking that it is a directory. If not, the lookup fails (5164-5168).(Locking ip is necessary not because ip->type can change underfoot—it can’t—butbecause until ilock runs, ip->type is not guaranteed to have been loaded from disk.)If the call is nameiparent and this is the last path element, the loop stops early, as perthe definition of nameiparent; the final path element has already been copied intoname, so namex need only return the unlocked ip (5169-5173). Finally, the loop looks forthe path element using dirlookup and prepares for the next iteration by setting ip =next (5174-5179). When the loop runs out of path elements, it returns ip.
File descriptor layer¶
One of the cool aspect of the Unix interface is that most resources in Unix arerepresented as a file, including devices such as the console, pipes, and of course, realfiles. The file descriptor layer is the layer that achieves this uniformity.
Xv6 gives each process its own table of open files, or file descriptors, as we saw inChapter 0. Each open file is represented by a struct file (3750), which is a wrapperaround either an inode or a pipe, plus an i/o offset. Each call to open creates a newopen file (a new struct file): if multiple processes open the same file independently,the different instances will have different i/o offsets. On the other hand, a single openfile (the same struct file) can appear multiple times in one process’s file table andalso in the file tables of multiple processes. This would happen if one process usedopen to open the file and then created aliases using dup or shared it with a child usingfork. A reference count tracks the number of references to a particular open file. Afile can be open for reading or writing or both. The readable and writable fieldstrack this.
All the open files in the system are kept in a global file table, the ftable. The filetable has a function to allocate a file (filealloc), create a duplicate reference(filedup), release a reference (fileclose), and read and write data (fileread andfilewrite).
The first three follow the now-familiar form. Filealloc (5225) scans the file tablefor an unreferenced file (f->ref == 0) and returns a new reference; filedup (5252) increments the reference count; and fileclose (5264) decrements it. When a file’s reference count reaches zero, fileclose releases the underlying pipe or inode, according tothe type.
The functions filestat, fileread, and filewrite implement the stat, read,and write operations on files. Filestat (5302) is only allowed on inodes and callsstati. Fileread and filewrite check that the operation is allowed by the openmode and then pass the call through to either the pipe or inode implementation. Ifthe file represents an inode, fileread and filewrite use the i/o offset as the offsetfor the operation and then advance it (5325-5326, 5365-5366). Pipes have no concept of offset. Recall that the inode functions require the caller to handle locking (5305-5307, 5324-5327, 5364-5378). The inode locking has the convenient side effect that the read and writeoffsets are updated atomically, so that multiple writing to the same file simultaneously cannot overwrite each other’s data, though their writes may end up interlaced.
Code: System calls¶
With the functions that the lower layers provide the implementation of most system calls is trivial (see sysfile.c). There are a few calls that deserve a closer look.
The functions sys_link and sys_unlink edit directories, creating or removingreferences to inodes. They are another good example of the power of using transactions. Sys_link (5513) begins by fetching its arguments, two strings old and new (5518).Assuming old exists and is not a directory (5520-5530), sys_link increments its ip->nlink count. Then sys_link calls nameiparent to find the parent directory andfinal path element of new (5536) and creates a new directory entry pointing at old’s inode (5539). The new parent directory must exist and be on the same device as the existing inode: inode numbers only have a unique meaning on a single disk. If an errorlike this occurs, sys_link must go back and decrement ip->nlink.
Transactions simplify the implementation because it requires updating multipledisk blocks, but we don’t have to worry about the order in which we do them. They either will all succeed or none. For example, without transactions, updating ip->nlinkbefore creating a link, would put the file system temporarily in an unsafe state, and acrash in between could result in havoc. With transactions we don’t have to worryabout this.
Sys_link creates a new name for an existing inode. The function create (5657)creates a new name for a new inode. It is a generalization of the three file creationsystem calls: open with the O_CREATE flag makes a new ordinary file, mkdir makes anew directoryy, and mkdev makes a new device file. Like sys_link, create starts bycaling nameiparent to get the inode of the parent directory. It then calls dirlookupto check whether the name already exists (5667). If the name does exist, create’s behavior depends on which system call it is being used for: open has different semanticsfrom mkdir and mkdev. If create is being used on behalf of open (type == T_FILE)and the name that exists is itself a regular file, then open treats that as a success, socreate does too (5671). Otherwise, it is an error (5672-5673). If the name does not already exist, create now allocates a new inode with ialloc (5676). If the new inode isa directory, create initializes it with . and .. entries. Finally, now that the data isinitialized properly, create can link it into the parent directory (5689). Create, likesys_link, holds two inode locks simultaneously: ip and dp. There is no possibility ofdeadlock because the inode ip is freshly allocated: no other process in the system willhold ip’s lock and then try to lock dp.
Using create, it is easy to implement sys_open, sys_mkdir, and sys_mknod.Sys_open (5701) is the most complex, because creating a new file is only a small part ofwhat it can do. If open is passed the O_CREATE flag, it calls create (5712). Otherwise,it calls namei (5717). Create returns a locked inode, but namei does not, so sys_openmust lock the inode itself. This provides a convenient place to check that directoriesare only opened for reading, not writing. Assuming the inode was obtained one wayor the other, sys_open allocates a file and a file descriptor (5726) and then fills in thefile (5734-5738). Note that no other process can access the partially initialized file since it s only in the current process’s table.
Chapter 5 examined the implementation of pipes before we even had a file system. The function sys_pipe connects that implementation to the file system by providing a way to create a pipe pair. Its argument is a pointer to space for two integers,where it will record the two new file descriptors. Then it allocates the pipe and installs the file descriptors.
Real world¶
The buffer cache in a real-world operating system is significantly more complexthan xv6’s, but it serves the same two purposes: caching and synchronizing access tothe disk. Xv6’s buffer cache, like V6’s, uses a simple least recently used (LRU) evictionpolicy; there are many more complex policies that can be implemented, each good forsome workloads and not as good for others. A more efficient LRU cache would eliminate the linked list, instead using a hash table for lookups and a heap for LRU evictions. Modern buffer caches are typically integrated with the virtual memory systemto support memory-mapped files.
Xv6’s logging system is woefully inefficient. It does not allow concurrent updatingsystem calls, even when the system calls operate on entirely different parts of the filesystem. It logs entire blocks, even if only a few bytes in a block are changed. It performs synchronous log writes, a block at a time, each of which is likely to require anentire disk rotation time. Real logging systems address all of these problems.
Logging is not the only way to provide crash recovery. Early file systems used ascavenger during reboot (for example, the UNIX fsck program) to examine every fileand directory and the block and inode free lists, looking for and resolving inconsistencies. Scavenging can take hours for large file systems, and there are situations where itis not possible to guess the correct resolution of an inconsistency. Recovery from a logis much faster and is correct.
Xv6 uses the same basic on-disk layout of inodes and directories as early UNIX;this scheme has been remarkably persistent over the years. BSD’s UFS/FFS and Linux’sext2/ext3 use essentially the same data structures. The most inefficient part of the filesystem layout is the directory, which requires a linear scan over all the disk blocks during each lookup. This is reasonable when directories are only a few disk blocks, but isexpensive for directories holding many files. Microsoft Windows’s NTFS, Mac OS X’sHFS, and Solaris’s ZFS, just to name a few, implement a directory as an on-disk balanced tree of blocks. This complicated but guarantees logarithmic-time directorylookups.
Xv6 is naive about disk failures: if a disk operation fails, xv6 panics. Whether thisis reasonable depends on the hardware: if an operating systems sits atop special hardware that uses redundancy to mask disk failures, perhaps the operating system seesfailures so infrequently that panicking is okay. On the other hand, operating systemsusing plain disks should expect failures and handle them more gracefully, so that theloss of a block in one file doesn’t affect the use of the rest of the files system.
Xv6 requires that the file system fit on one disk device and not change in size. Aslarge databases and multimedia files drive storage requirements ever higher, operating systems are developing ways to eliminate the ‘‘one disk per file system’’ bottleneck. Thebasic approach is to combine many disks into a single logical disk. Hardware solutionssuch as RAID are still the most popular, but the current trend is moving toward implementing as much of this logic in software as possible. These software implementations typically allowing rich functionality like growing or shrinking the logical deviceby adding or removing disks on the fly. Of course, a storage layer that can grow orshrink on the fly requires a file system that can do the same: the fixed-size array of inode blocks used by Unix file systems does not work well in such environments. Separating disk management from the file system may be the cleanest design, but the complex interface between the two has led some systems, like Sun’s ZFS, to combine them.
Xv6’s file system lacks many other features in today file systems; for example, itlacks support for snapshots and incremental backup.
Xv6 has two different file implementations: pipes and inodes. Modern Unix systems have many: pipes, network connections, and inodes from many different types offile systems, including network file systems. Instead of the if statements in filereadand filewrite, these systems typically give each open file a table of function pointers,one per operation, and call the function pointer to invoke that inode’s implementationof the call. Network file systems and user-level file systems provide functions that turnthose calls into network RPCs and wait for the response before returning.
Exercises¶
- why panic in balloc? Can we recover?
- why panic in ialloc? Can we recover?
- inode generation numbers.
- Why doesn’t filealloc panic when it runs out of files? Why is this more common and therefore worth handling?
- Suppose the file corresponding to ip gets unlinked by another process betweensys_link’s calls to iunlock(ip) and dirlink. Will the link be created correctly?Why or why not?
- create makes four function calls (one to ialloc and three to dirlink) thatit requires to succeed. If any doesn’t, create calls panic. Why is this acceptable?Why can’t any of those four calls fail?
- sys_chdir calls iunlock(ip) before iput(cp->cwd), which might try to lockcp->cwd, yet postponing iunlock(ip) until after the iput would not cause deadlocks.Why not?